




Introduction
Unsupervised learning is the process of analyzing data without having a specific outcome in mind. Instead of trying to identify patterns or trends, you’re using machine learning algorithms to discover relationships between elements within your dataset. The goal is to find associations between items and groups of items that will help you better understand your data and make predictions about future behavior. For example, unsupervised learning can be used to determine which customers are likely to buy certain products based on past purchases. In this article we’ll discuss some common applications of unsupervised machine learning methods like clustering and association rule mining, as well as how they can benefit different types of businesses
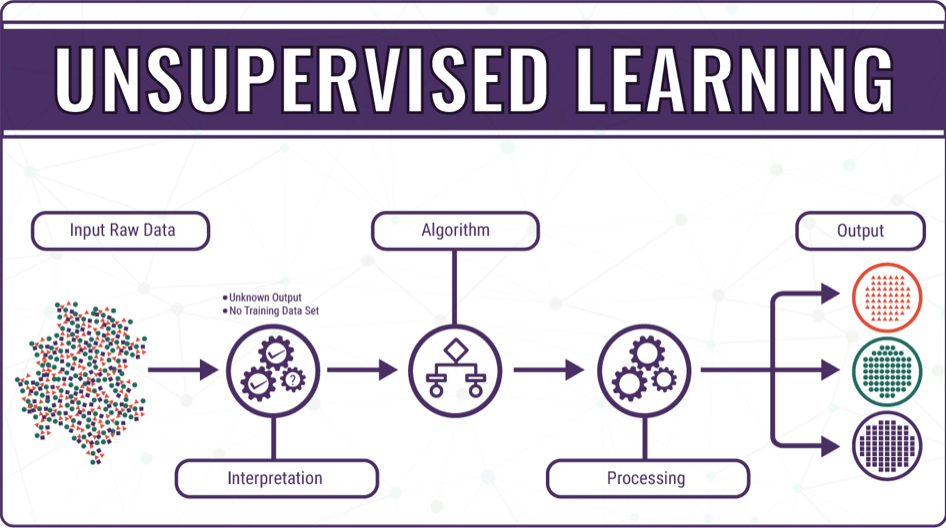
What is unsupervised learning?
Unsupervised learning is a type of machine learning that uses data to make predictions about the future. This is different from supervised learning, where you have labeled data and use it to train your model. In unsupervised learning, you don’t have any labels for your data–you just have raw information that can be analyzed and used to make predictions on its own.
For example: You might want to know how many customers will buy your product over time so that you can plan future production levels accordingly. With supervised learning methods (like classification), we would need some way of identifying which customers are likely buyers before they actually buy anything; this could be done by analyzing past purchases or user behavior patterns but would require labeling each customer with their predicted outcome status (i.e., whether or not they bought). With unsupervised methods (like clustering), we could just look at all our current customers together without any labels attached — then separate them into groups based on similar characteristics such as age range or income level — and use those clusters as predictors instead!
Why use unsupervised learning?
Unsupervised learning is used to find patterns in data and make predictions without labels. Unsupervised learning can be used to identify trends, detect anomalies and make recommendations based on past behavior. It’s also commonly used for data cleaning, where you want to identify outliers or missing values in your dataset before building a supervised model.
Unsupervised learning can be applied at different stages of the machine learning process:
- Preprocessing – Unsupervised preprocessing techniques include dimensionality reduction techniques like Principal Component Analysis (PCA) or Singular Value Decomposition (SVD) that reduce the number of features without any prior knowledge about what features are important for predicting outcomes;
- Training – In this stage we build an unsupervised neural network by feeding it lots of training examples where we already know the answer but don’t provide labels when presenting new examples; The goal here is just getting good estimates for weights so we can predict future outcomes based on these weights alone; Finally once trained we need some way
Unsupervised Learning Algorithms and Applications
Unsupervised learning is a machine learning technique that enables computers to learn from data without being given answers to questions. It is often used for clustering and dimensionality reduction. Unsupervised learning can be used in many different applications such as:
- Classification – Classifying objects into categories, such as identifying which customers are likely to buy a particular product based on their purchase history or current shopping cart contents
- Regression – Predicting continuous variables like price or age from categorical variables such as customer segmentation (e.g., male vs female)
Image Recognition and Analysis
As you can see, unsupervised learning has a lot of potential. It’s not limited to just one application and can be used in many different scenarios. Now that you know what it is and how it works, let’s look at some examples of how this type of machine learning can be applied in your everyday lives!
Image Recognition and Analysis:
Unsupervised learning techniques have been used for decades by scientists who study animal behavior in order to better understand their natural environment. For example, if you wanted to find out where animals live on a given island or continent (or planet), then an unsupervised approach would allow you collect images from multiple locations with little human intervention required beyond collecting the images themselves.[1] Then once these data sets are collected together into one large database called “image repository”,[2] they can be analyzed using regression models like linear regression while also accounting for noise introduced by weather conditions at each location.[3] By doing this type of analysis over time as new pictures come available every day will help us learn more about our planet’s biodiversity without needing any supervision from humans other than telling them which types of animals might exist somewhere else besides here today because we want them too much!
Recommender Systems
Recommender systems are a type of unsupervised learning that uses historical user data to recommend content. They can be used in ecommerce and social media applications, as well as many others.
Recommender systems work by predicting what users want to see or hear next, based on their past viewing or listening habits. This can include recommending movies, books, music and more–even if you’re not sure what you want!
Text Data Analysis
Unsupervised learning is used to analyze text data in many different ways. For example, you can use unsupervised learning to cluster documents into groups based on their content or structure. You can also use unsupervised learning to identify common topics within a set of documents or sentences, which may then be used as features when building predictive models.
Recommendation Engines
Recommendation Engines
Recommendation engines are a type of machine learning algorithm that help you to predict what products or services a user might like based on their past behavior. They can be used in many different industries, from e-commerce to healthcare and beyond. A well-built recommendation engine will improve your user experience by giving them better recommendations than they would get if you didn’t use one at all. For example, if a user buys two shirts from your website but never buys anything else despite browsing around for hours on end, then there’s probably something wrong with how those initial shirt recommendations were made (or perhaps there was an issue with delivery). A good recommendation engine would have shown this particular customer some other options (such as pants or jackets) before recommending more shirts again!
Unsupervised learning can help improve data analysis, regardless of whether your data is labeled or not.
Unsupervised learning is a form of machine learning that can be used to find patterns in data. Unsupervised learning does not require labeled data, but rather it finds patterns in unlabeled or “unlabeled” datasets. This type of analysis is useful for finding anomalies, detecting fraud and discovering hidden insights about your business.
Using unsupervised learning on your own data can help you better understand the underlying structure within your business or industry. It also allows you to find new ways to group customers together based on similarities between them (as opposed to grouping them based on differences).
Conclusion
Unsupervised learning is a topic that can be confusing for many people. It’s not as straightforward as supervised learning, which requires labeled data, and it doesn’t always have clear applications like deep learning does. But unsupervised learning is still an important part of machine learning and data analysis–and it can help improve your results regardless of whether your data is labeled or not!
More Stories
Popular Machine Learning Code Snippets (Demo)
What Is Supervised Learning For All The People In The World Out There
An Introduction to Machine Learning